Hypothesis testing from scratch: the logic before the formula
The Underlying Idea
A product team runs an A/B test. The new checkout flow shows a 2.7% conversion rate versus 2.4% on the control. The p-value comes back at 0.03. Someone declares it significant, the feature ships, and three months later conversion is flat. What went wrong?
Not the math. The math was fine. What went wrong was that nobody in that room understood what they were actually doing when they ran the test.
Hypothesis testing is designed for a specific problem: you observe something in data and you want to know whether it reflects a real signal or whether it could plausibly have happened by chance, even if nothing was going on. You can’t answer that directly. The counterfactual (the world where nothing changed) is invisible. So you do something indirect.
You assume nothing is going on. You calculate how likely your observation would be under that assumption. Then you decide whether your data is too strange to be consistent with that assumption.
That’s the entire logical structure. The formulas, the distributions, the test statistics: all of it is machinery for executing that logic precisely. If you don’t have this structure clear first, the machinery produces numbers you’ll misread.
Historical Root
The framework most analysts use today was stitched together from two incompatible theories, and the seam still shows.
Ronald Fisher built the foundational concept of the p-value in the 1920s while working at Rothamsted Experimental Station, an agricultural research institution in England. He was trying to give scientists a systematic way to evaluate experimental results. His 1925 book Statistical Methods for Research Workers introduced both the null hypothesis and the p-value as a continuous measure of evidence. For Fisher, the p-value was a tool for inductive reasoning, a way to calibrate how surprising your data was. It was not a binary decision rule.
Jerzy Neyman and Egon Pearson developed a different framework in the late 1920s and early 1930s. They weren’t interested in measuring evidence. They wanted to make decisions with controlled error rates. They introduced the alternative hypothesis, the concepts of Type I and Type II error, and statistical power. Their framework was explicitly about long-run behavior: use this procedure consistently across many experiments, and you’ll make the wrong call at most proportion of the time.
These two frameworks are philosophically incompatible. Fisher thought Neyman-Pearson missed the point of scientific inference. Neyman thought Fisher’s p-values were imprecise. What most statistics courses teach (state a null, choose , compute a p-value, reject if ) is a compromise that neither man fully endorsed. The confusion in modern practice isn’t accidental. It was built into the framework from the start.
Key Assumptions
Hypothesis testing breaks down in predictable ways when these conditions aren’t met.
The null hypothesis must be specified before seeing the data. The p-value is calculated under the assumption that the null was fixed in advance. If you look at your results first and then construct a hypothesis to test, you’ve contaminated the procedure. The p-value no longer means what the formula says it means.
The test statistic must have a known null distribution. To calculate a p-value you need to know what distribution your test statistic follows when the null is true. That requires assumptions, typically independence, identical distribution, sometimes normality. Violate these and the null distribution is wrong, which makes your p-value wrong.
Sample size must be committed to before collection. Stopping data collection when results become significant (optional stopping) inflates the Type I error rate above . The math assumes a fixed sample size. If you check results repeatedly and stop when , you’re running a different procedure than the one you’re evaluating.
Observations must be independent. Standard tests assume that one observation doesn’t influence another. Clustered data, repeated measurements, and time series all violate this. Running a t-test on correlated observations produces standard errors that are too small, making results look more significant than they are.
Statistical significance is not causal identification. A significant result tells you something unusual happened relative to the null. It says nothing about what caused it. Confounding, measurement error, and selection bias can all produce significant p-values that have nothing to do with your hypothesis.
The Math
The Setup
Let denote the null hypothesis, the default assumption that there is no effect, no difference, no relationship. Let denote the alternative hypothesis, the claim you’re evaluating evidence for.
You collect data and compute a test statistic , a function of the data chosen so its distribution under is known:
The p-value
The p-value is the probability of observing a test statistic at least as extreme as the one you computed, given that the null is true:
where is the random variable representing the test statistic and is your computed value. The absolute values apply to two-tailed tests. For a one-tailed test, the inequality is directional.
A small p-value means: if the null were true, data this extreme would be rare. It is not the probability that is true. It is not the probability that your result will replicate. It is a conditional probability, conditional on being true.
Decision Rule and Error Types
Before seeing the data, you choose a significance level : the maximum tolerable probability of rejecting a true null. The convention is arbitrary. It comes from Fisher writing in the 1920s that two standard deviations felt like a reasonable threshold. There’s no deeper reason.
The decision rule:
This generates two possible error types:
| True | False | |
|---|---|---|
| Reject | Type I error (false positive, rate ) | Correct (power ) |
| Fail to reject | Correct | Type II error (false negative, rate ) |
Statistical power is : the probability of correctly rejecting a false null. It depends on sample size, effect size, and your chosen . Low-power tests miss real effects. This problem historically gets less attention than false positives but causes just as much damage in practice.
The Test Statistic in Practice
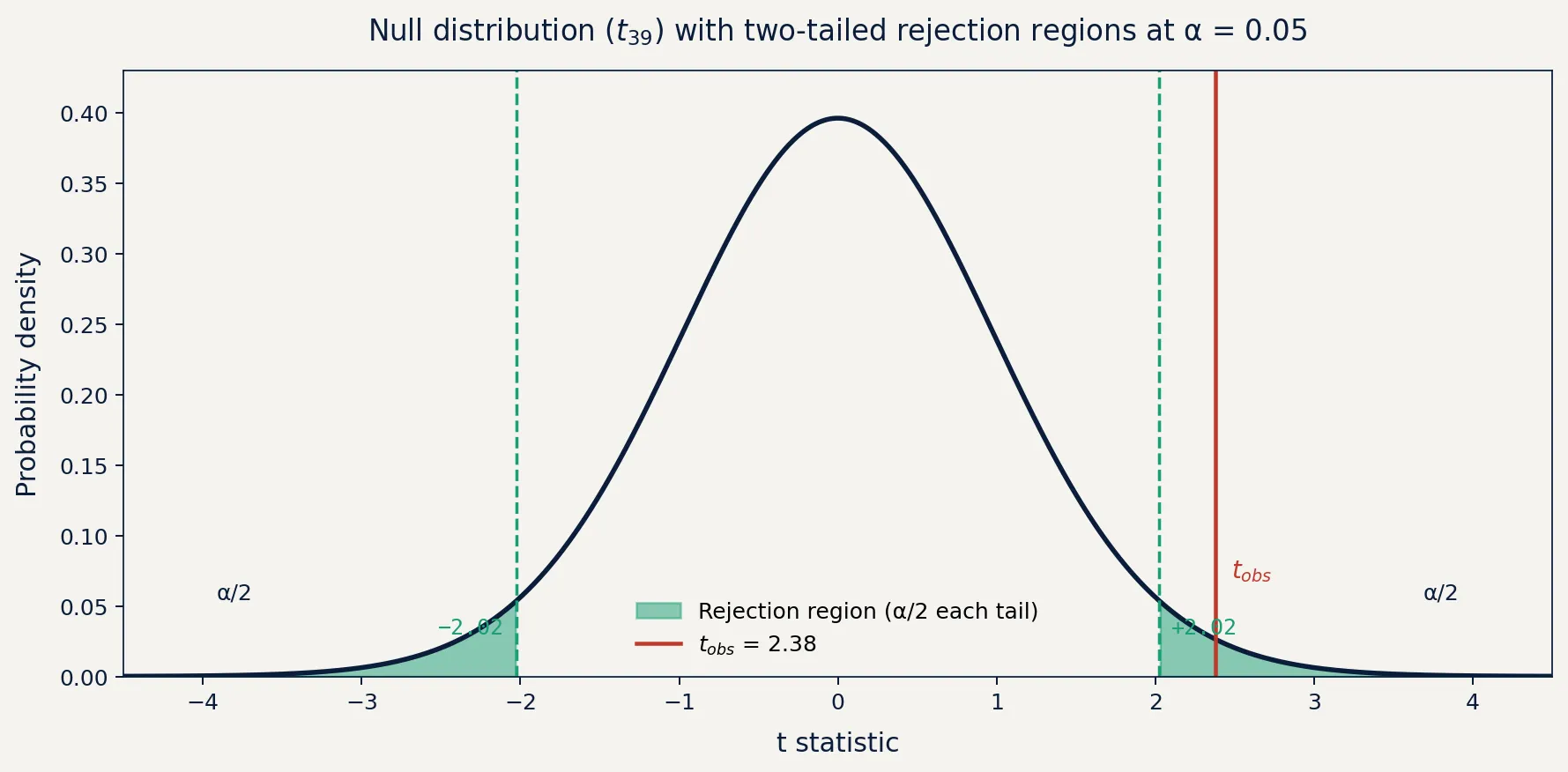
For a one-sample test of a mean with unknown variance (the common case), the test statistic is:
where is the sample mean, is the null hypothesis value, is the sample standard deviation, and is sample size. Under , this follows a t-distribution with degrees of freedom.
The specific formula changes depending on the test. z-tests, chi-squared, F-tests, and likelihood ratio tests all have different statistics and null distributions. The logic doesn’t change. You always ask: how extreme is this observation, assuming nothing is happening?
The Code
The following builds hypothesis testing from scratch, computing the test statistic and p-value manually so you can see exactly what’s happening inside a function like scipy.stats.ttest_1samp.
import numpy as np
from scipy.stats import t as t_dist
# Scenario: did daily active users change after a product update?
# Null hypothesis: mean DAU = 1000 (no change)
np.random.seed(42)
n = 40
sample = np.random.normal(loc=1045, scale=120, size=n) # true effect: +45 users
# Pre-specified before data collection
mu_0 = 1000
alpha = 0.05
# Compute test statistic
x_bar = np.mean(sample)
s = np.std(sample, ddof=1) # sample std dev (ddof=1 corrects for bias)
se = s / np.sqrt(n) # standard error of the mean
t_stat = (x_bar - mu_0) / se
# p-value: two-tailed test
df = n - 1
p_value = 2 * t_dist.sf(np.abs(t_stat), df=df)
print(f"Sample mean: {x_bar:.2f}")
print(f"Test statistic: t = {t_stat:.4f}")
print(f"p-value: {p_value:.4f}")
print(f"Decision: {'Reject H0' if p_value < alpha else 'Fail to reject H0'}")With a true effect of +45 users and , the test rejects the null most of the time, but not always. Sample variance introduces real uncertainty. To verify the false positive rate, rerun with loc=1000 (no true effect) across many simulations. You should see rejection roughly 5% of the time. That’s not a bug. That’s what means.
Business Application
Where this applies
Hypothesis testing belongs in any decision where you need to separate signal from noise in measured data:
- Product: A/B tests on conversion, retention, activation. The test tells you whether observed lift is consistent with random variation, not whether you should ship.
- Finance: Testing whether a strategy’s returns exceed a benchmark. A significant t-stat on a backtest is necessary but not sufficient. It doesn’t account for look-ahead bias or overfitting.
- Operations: Evaluating whether a process change reduced defect rates. With small samples and high variance, you need to know the test’s power before concluding “no significant improvement” means no improvement.
- Regulated contexts: Drug approval, device evaluation, and public health decisions build significance levels and power calculations into study design before a single subject is enrolled.
Where it breaks down
Misreading the p-value is the most costly mistake in practice. Back to the checkout example: doesn’t mean there’s a 97% chance the effect is real. It means that if the null were true (if there were no actual difference) you’d see a gap this large or larger about 3% of the time by chance. Those are different statements. Plenty of business decisions have been made on the first reading of the second statement.
Non-significant does not mean no effect. If the test doesn’t reject the null, you haven’t shown the null is true. You’ve shown the data was insufficient to reject it. A test on 200 users looking for a 0.2% lift has roughly zero power. “No significant difference found” in that context is nearly meaningless.
Multiple comparisons compound quickly. Test 20 independent metrics at and you expect one false positive just by chance. If your analytics platform tracks 50 metrics automatically and flags significant changes, it will find roughly 2-3 spurious results every week even when nothing is going on. Use Bonferroni correction, Benjamini-Hochberg, or better yet pre-register your primary metric before the experiment runs.
Optional stopping is common and almost always unacknowledged. Watching a dashboard and calling a test when it crosses inflates your actual false positive rate far above . Sequential testing methods exist for exactly this situation. They adjust the threshold as you accumulate data.
The framework is precise. The assumptions are specific. Get either wrong and you have a number that looks rigorous but isn’t.